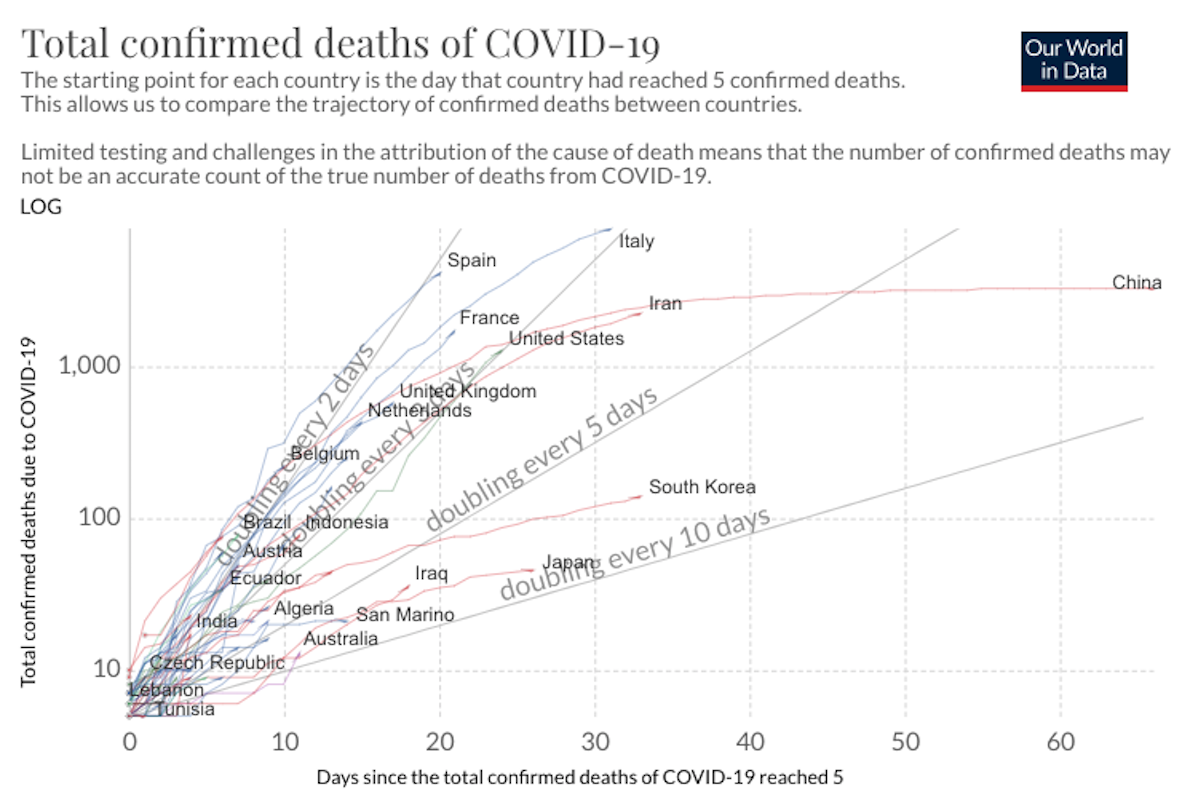
COVID-19 Science Update for March 27th: Super-Spreaders and the Need for New Prediction Models
Absent isolation or other precautionary measures, the average socially active COVID-19 infectee will transmit the disease to an average of about 2.4 people. i.e., the R0 value is 2.4. But super-spreaders can spread a disease to dozens or hundreds.
· 11 min read
{kind=link}
Keep reading
A Beautiful Odyssey, Made Dreary By Remorse
Charlotte Allen
· 14 min read


Men Without Meaning
Tanveer Ahmed
· 10 min read

The Rise of Sainte-Marie Among the Hurons
Greg Koabel
· 21 min read


Blood, Progress, and Amnesia
Jason Manning
· 9 min read
