News
COVID-19 Science Update for March 25th: Understanding Models
This clustering phenomenon explains why the COVID-19 policy debate among politicians, doctors, and pundits now has become somewhat surreal, with world-class experts telling us either that we are facing an “apocalypse,” or that the pandemic will fizzle and we’re all “going to be fine.”
{kind=link}
The latest global data for COVID-19—updated with reports received on March 25th, 2020—have been published at Our World in Data. Here are some of the numbers and trends that I believe deserve special attention, as well as a brief report on notable developments and analyses. Since March 21st, these updates have been published at Quillette in our section marked COVID-19 UPDATES. Please report needed corrections or suggestions to [email protected].
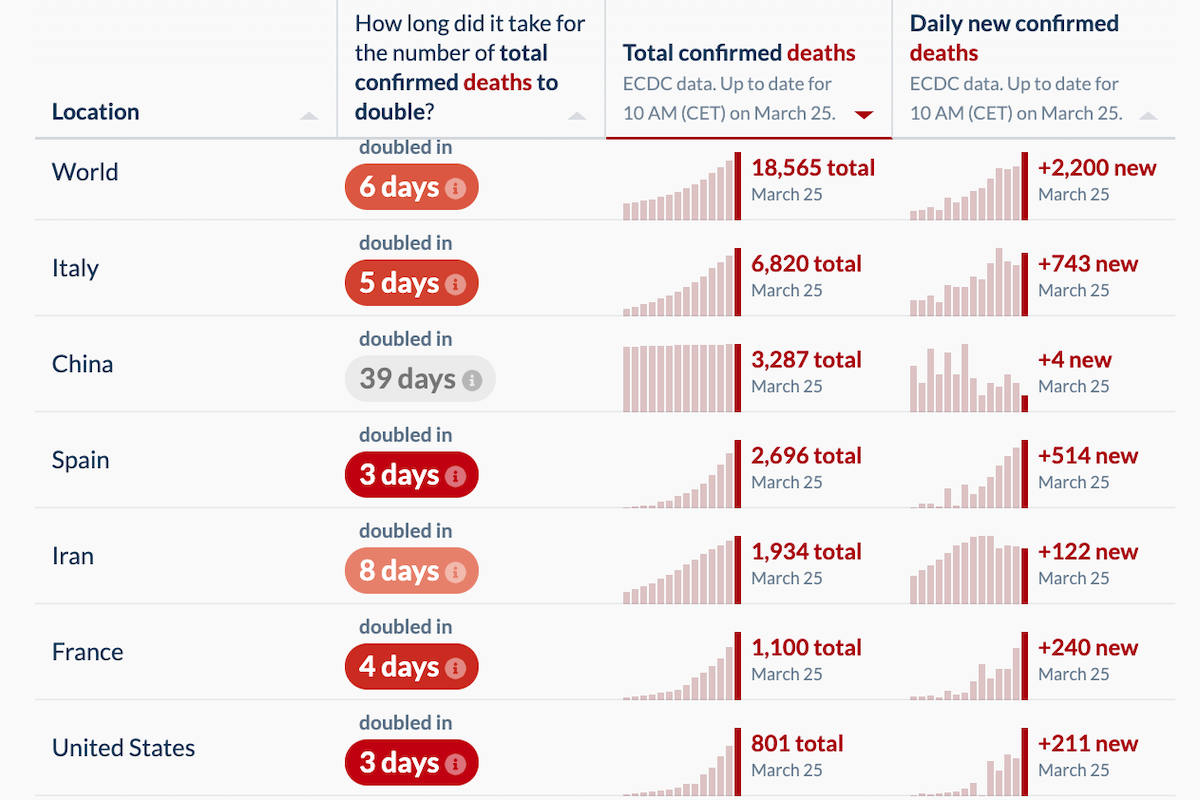
The number of newly reported deaths increased yesterday. There were 2,200 new confirmed COVID-19 fatalities, compared to 1,764 reported on Tuesday, 1,660 on Monday, and 1,690 on Sunday. This was largely due to increased death tallies in France (240 new deaths, up from 186 the day before), Italy (743, up from, in reverse order, 601, 649, and 795), Spain (514, up from 462) and the United States (211, up from 119).
The Netherlands had an unsettling jump to 63 new deaths (up from 34 on Tuesday). And some bad news in Sweden, which I discussed yesterday as being a European outlier due to its liberal approach amid the COVID-19 pandemic: 11 new deaths, representing an almost 50 percent jump in its total cases.
Keep reading

A Crisis in the Humanities

The Pacific's True Rogue State


The Rise and Fall of Graham Platner

Reshaping the Middle East
