Science / Tech
Move 37 and the Coming Mindhack
What happens when human manipulation arrives at its Claude Mythos moment?

{kind=link}
In March 2016, the world was about to watch a paradigm shift. Google Deepmind’s AlphaGo team challenged Lee Sedol, the world champion of Go, to a competition. Go is the oldest and most complex strategy game ever created, played continuously for over 2,500 years. It has more possible board positions than there are atoms in the universe, and it was considered the exclusive province of the human mind. Researchers guessed that AI was at least a decade away from competing at the top level.
Sedol predicted that he would win in a landslide. He lost the first game. In the second game, on move 37, AlphaGo made a move that made no sense to anyone watching. Sedol got up and left the room for fifteen minutes. Commentators thought it was a mistake, a clear vindication of human superiority. But it wasn’t a mistake. The AI was playing in a part of the game that the human mind had never explored. This seminal moment showed us that, after 2,500 years, people have still not fully understood the game they invented. We have been playing in a corner of the probability space, and mistaking it for the whole map.
Sedol retired from professional Go three years later. In a reflection published this year, he called the match “a guide that presented the future in advance” and said it “sent a clear signal to humanity about how the world would change.” A year later, AlphaGo Zero—which was not trained on human games, just on the rules for three days—defeated the earlier AlphaGo 100:0.
I think about Move 37 a lot. I think about what it means when the map you thought was complete turns out to be almost empty.
Enter Claude Mythos
Before Anthropic announced Claude Mythos, information about the model had already leaked online, so it didn’t come as a complete surprise. The model is so good at finding security exploits that they won’t be releasing it publicly. Their previous top model, Claude Opus, was not particularly good at finding actual security exploits. In internal testing, Mythos was able to turn identified vulnerabilities into working exploits in roughly 72.4 percent of cases within a controlled benchmark environment. In just a few weeks, it found hidden security flaws known as zero-day vulnerabilities in major operating systems and web browsers, many of which were in active code for between ten and twenty years.
It found a sixteen-year-old bug in FFmpeg that had eluded detection after it was hit five million times by autonomous testing tools. It casually wrote a browser exploit that chained together four vulnerabilities, which would give an attacker the ability to run code on a user’s system just by visiting a webpage. In just four hours, it wrote a remote root exploit to a server without any formal security training from the human directing it. In response, Anthropic announced Project Glasswing, a coalition of the biggest players in software, AWS, Apple, Google, Microsoft, Crowdstrike, NVIDIA, and others, aimed at patching the vulnerabilities.

The glasswing butterfly’s defence mechanism is transparency. With transparent wings, it hides from the world, and despite a delicate appearance can carry up to forty times its weight. However, the analogy breaks down almost immediately. The glasswing’s transparency makes it invisible and harder to find, but the transparency of a leaked exploit is a target, broadcasting a vulnerability to the entire world. Mythos is Move 37 for computer security. It shows us that we’ve been playing in a tiny corner of the map, apparently besting decades of security research in a matter of days.
Defence Can’t Keep Up
I am glad that Anthropic exists. Its founders have concluded that exponential intelligence growth was inevitable and they have committed to entering the race in the hope of avoiding catastrophe. I know many people at Anthropic and I have been encouraged by the company’s ability to act responsibly within a capitalist framework. The ethical commitments derive from the personalities of the people who work there. But good intentions are a gamble, and we should consider the scale of what they’re up against:
- OSS-Fuzz, an automated technique for bug-finding that began in 2016, has found about 13,000 vulnerabilities in ten years.
- Human researchers find a few per target per year.
- Anthropic says Claude Opus found more than 500 in a few weeks.
- Early experiments with Mythos suggest it can find thousands in a few weeks, at drastically lower cost per bug than the previous kinds.
This is a fundamentally different kind of threat, and it heralds a step-change in computing that might be even more significant than the introduction of ChatGPT or Claude Code. This kind of race is rigged against a defensive player for five reasons.
1. Other Labs Are not Far Behind
OpenAI, Deepseek, and other AI companies are just behind Anthropic and will soon develop models with this type of capability. Open-source models won’t be too far behind. In some domains, smaller models are approaching the capabilities of last year’s systems.
2. AI Will Only Get Better
This refrain reminds us that our priors and expectations will be disrupted time and time again by exponential progress. People are very bad at reasoning about exponential progress. We tend to assume that tomorrow will be like today. When it’s not, we experience shock and then quickly reset our baseline. We don’t easily internalise how more step changes could drastically change our world. It’s hard to imagine that AI won’t get better for the foreseeable future, and it doesn’t even require the model itself to get better.
AI models improve drastically when prompted better and connected to the right data. If a model has all your essays it can think of ideas that you’ll like more and sound more like you. Improving the harness, the way a model is prompted, looped, and shown data, makes a tremendous impact.
The current mind-blowing results came from running Mythos in a very simple loop with a one-paragraph prompt. Connecting Mythos to massive amounts of data, giving it lists of previous exploits, and putting it in collaboration and competition with other versions of itself could produce an order of magnitude more exploits.

3. You Can’t Just Discover all the Bugs
Thousands of people have used LLMs for the same task and produced drastically different results. When I run Claude in a loop it sometimes doesn’t figure out something important until the fifteenth iteration. LLMs are not deterministic. Each time you prompt them, they travel a different path through their big brains. They are dramatically affected by your approach and ideas for how to solve a problem. This is one of the things that makes them so unpredictable, spontaneous, and anthropomorphic.
So the first time it might find ten exploits, the second time another ten. Prompting it in different directions and guiding it slightly differently can unlock new ones. You could run it 1,000 times and find new bugs each time, with no guarantee that it has found them all.
4. There May Not Be a Ceiling to the Number of Exploits
“It’s quite possible,” Facebook’s former chief information security officer said two weeks ago, “that all this development we’ve done in memory-unsafe languages, without formal methods, that none of that is actually secure in the presence of superintelligent bug-finding machines. In which case we need to be massively rebuilding the base infrastructure we all work on. And nobody is doing that.” Security researcher Thomas Ptacek has added: “We’ve been shielded from exploits not by soundly engineered defenses, but by a scarcity of elite attention. Most software has never been seriously examined by anyone with the skill to break it. AI eliminates that scarcity.”
How many exploits are out there total? The truth is that nobody really knows. Memory bugs in old languages might be finite, but there are so many other types of exploits. There may be a finite number of those too, and it may be possible to write a perfectly secure piece of code. But it may be that it isn’t. Most likely, given that we’ve just started to explore these classes of advanced exploits, the ceiling is at least so far away as to be presently irrelevant.
It really may be that each new generation of model expands the ceiling, gaining visibility into a new world of vulnerabilities that the previous model could never have even imagined.

5. Sticky LLMs and Stuck Paradigms
LLMs are sticky. Once they choose a direction and decide that something is true, it’s extremely hard for them to see different directions. If the LLM concludes that a certain set of well-scoped user permissions will make a system secure, it’s not as likely to realise it’s wrong mid-process. Adversarial review can help. When a second model or group of models is asked to poke holes in an approach, it often finds things the original model missed. But these adversarial reviewers are still stuck in the paradigm of the application.
Compare that to an attacker LLM, trained on all the different ways code goes wrong, watching every bug fix on Github, finding an exploit in one piece of code and looking for similar ones in every piece of software. It can apply thousands of attack paradigms. And it just needs to poke one hole. An attacker just needs one exploit to work in thousands of attempts. A defender, on the other hand, needs every single patch to be correct. The math is asymmetric, and stickiness makes it worse.
“But We’re Fixing the Bugs!”
Anthropic has committed US$100m in usage credits and US$4m in donations to open-source security groups. Some of the brightest minds on Earth are presently focused on the task. The sixteen-year old bug in FFmpeg has already been patched! But it’s much easier to poke a hole in a boat than it is to fix it, especially when the hole is in millions of boats that are out sailing somewhere. Security response is intrinsically slower, harder, and more expensive than exploit creation.
Just two or three of the 500 zero-day bugs Anthropic says it identified using Opus 4.6 in February 2026 have been fixed. It’s not the software developer’s fault. It’s structural. Finding and fixing bugs is hard.
Dan Kaminsky and the Thirteen Days
In early 2008, a brilliant security researcher named Dan Kaminsky discovered an exploit in DNS, the protocol that connects the entire internet. He immediately convened a secret meeting of sixteen security researchers at Microsoft headquarters and then coordinated a massive, multi-vendor response involving dozens of major technology companies. A patch was released on 8 July. It was the largest synchronised security update in the history of the internet. Those involved hoped to keep the exploit secret for thirty days after the patch was made available, but news leaked into the wild after thirteen days. That was one vulnerability. Imagine thousands of new ones in similarly critical systems, with more emerging each month.

The Y2K Bug
Some of you remember the 1990s, those halcyon days when neon was in and dates were stored as two-digit numbers. We had known since the ’60s that this would eventually break and potentially cause tremendous damage, but it wasn’t until the mid-’90s that people started treating the bug as a crisis. In 1993, it was estimated that the bug would cost US$50–75bn to mitigate worldwide. In 1998, response work began in earnest. The actual cost was closer to US$308bn. This was one class of bug, known decades in advance, with a countdown and a forcing function. But it was in every system, in spaghetti string code, with developers who had left or forgotten or passed away.

The Heartbleed Bug
Heartbleed was a critical vulnerability in OpenSSL that affected a large share of the web’s HTTPS infrastructure, since OpenSSL powered roughly two-thirds of sites at the time. Security researchers tried a new approach, releasing the patch with great fanfare on the same day they announced the exploit. Two months later, 300,000 servers were still vulnerable. Five years later, 91,000 servers were still vulnerable. One bug. A giant marketing campaign. And this was servers, sysadmins, not end users. And still it didn’t get patched in many places.
COVID-19
When COVID-19 began spreading and sickening people in Wuhan in late 2019, many people had a hard time understanding exponential growth and didn’t respond until the problem was at our doorstep and it was too late. I remember watching people die in Italy and seeing complete nonchalance in California until just a few days before things got really bad. It was also much easier to get infected than it was to prevent infection; much easier to poke one hole than seal all the holes. Right now, 99 percent of the exploits found by Mythos remain unpatched. This is not our fault. It’s certainly not Anthropic’s fault. This stuff is just structurally difficult.
The Patches Don’t Reach
The FFmpeg bug was discovered within weeks, and a patch has already been shipped. FFmpeg is open-source code that powers almost every tool that encodes or decodes video. Nearly every video player, browser, phone, app, and streaming service has a version of it embedded in their software. I had Claude search my computer, and these are the fifteen versions I have:
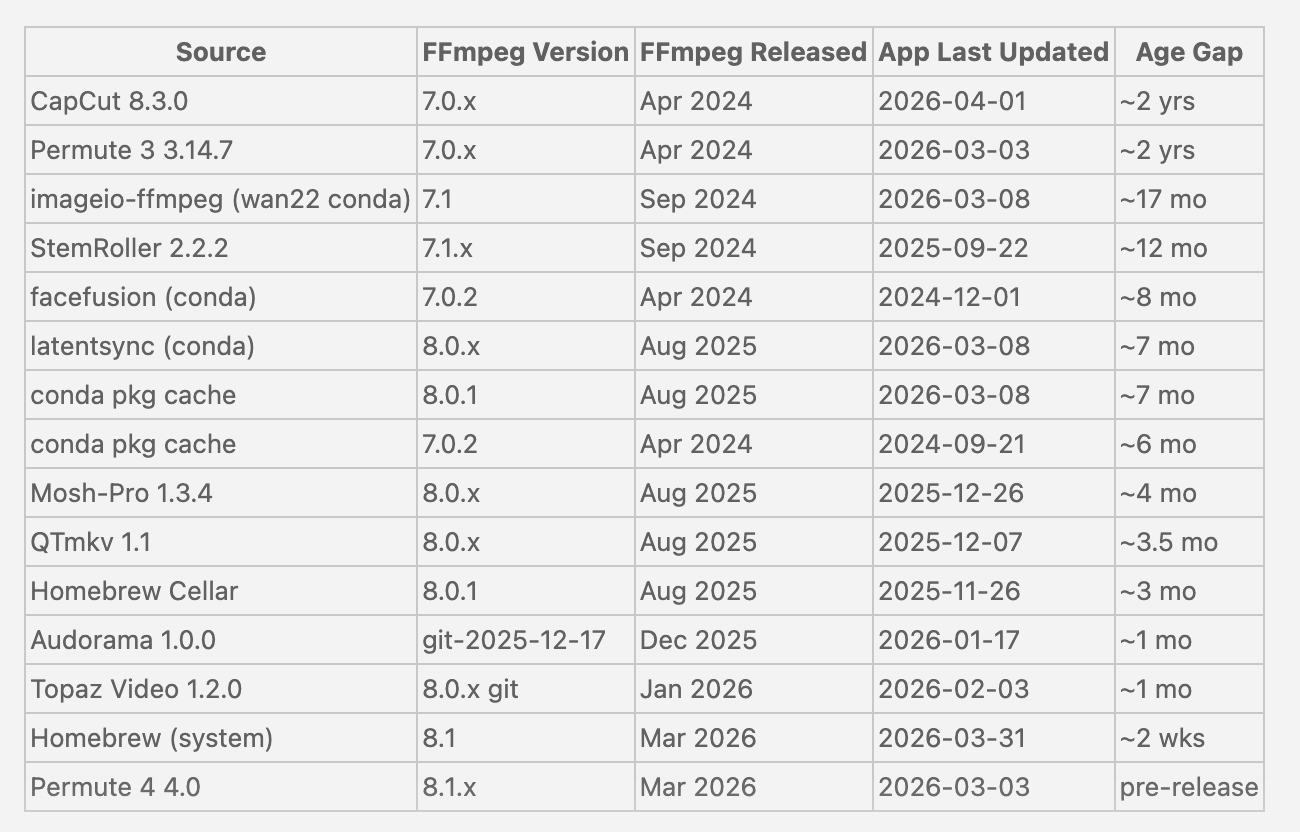
Fifteen versions of FFmpeg! Capcut, released just a week ago, has a version that is two years old! To be immune from this single vulnerability, I would need to (a) Know that the vulnerability exists, and which software uses the code (b) Stop using that software until a patch is made and the software integrates it and I update. What about an old video game or smartphone that doesn’t release updates anymore? When was the last time you updated FFmpeg?
Typically, large legacy systems are the ones that take forever to patch. Critical infrastructure that protects money, electricity, defence, etc. can’t be updated five times a day by a vibe coder. It’s too risky. And if an attacker can own a bunch of legacy systems, they can then get into the trusted chain and attack your patched system through there. Even if you update everything, you’re still vulnerable.
The SolarWinds attack offers an instructive example. An IT company distributing software to more than 30,000 organisations had its internal network compromised. The attackers injected code into a software update, which went out through trusted channels and installed backdoors on the network. About 18,000 organisation installed the compromised update and attackers were inside networks of the Department of State, Treasury, Energy, Homeland Security, and the NSA for months before they were discovered.
It’s a lot harder to, say, get root access to a remote server over the internet with which you have no relationship. So imagine a chain of four vulnerabilities makes this easy, and it propagates across the internet. Most servers update, but it’s easy to tell which ones haven’t. And attackers have another three sets of four-chain exploits ready to go for when a server gets patched. Attackers can use this surface, which your computer trusts, to push an attack onto your computer. Because it’s travelling over a trusted network, that code doesn’t need to use such sophisticated attacks to hack you.

Move 37 for Your Brain
We think we understand how human persuasion works. Emotional triggers, in-group identities, thought and perception errors. We think we have the map. But consider that some of the now-familiar sentence structures we call “clickbait” were not popularised and systematised until 2013.
In 1994, a behavioural economist at Carnegie Mellon named George Lowenstein theorised that provoking curiosity in a headline might create more impact. But it wasn’t until 2013, when Upworthy built a massive A/B testing infrastructure to discover what kinds of headlines worked best, that formulations like “You Won’t Believe What Happens Next” were essentially discovered. And with that development, the playspace expanded ever so slightly.
Keep reading
Capturing the ‘Odyssey’
Biting the Hand
Sex Differences Above the Neck

A Beautiful Odyssey, Made Dreary By Remorse

